By Ellie Good | Head of Product, Oraion

Across government, logistics, manufacturing, and financial services, a consistent pattern has emerged in enterprise AI deployment: the failures are not failures of the technology. The root cause is almost always structural — organisations attempting to run enterprise AI on data infrastructure that was never designed for it.
The research backs this up. A March 2026 study by Harvard Business Review Analytic Services and Cloudera found that only 7% of enterprises consider their data completely ready for AI — and 73% report actively struggling with AI data preparation. Gartner predicts that through 2026, organisations will abandon 60% of AI projects due to insufficient data quality. MIT's GenAI Divide report found that of enterprises that evaluated purpose-built AI systems, only 5% made it to production — most failing due to brittle workflows and lack of contextual grounding. PwC's 2026 Global CEO Survey found that 56% of CEOs say their company has seen neither higher revenues nor lower costs from AI.
The gap isn't enthusiasm or budget. Writer's 2026 Enterprise AI Adoption Survey found that 59% of companies are spending over $1 million annually on AI — yet only 29% see significant organisational ROI. Datadog's State of AI Engineering report (April 2026), drawing on real production telemetry, found that 1 in 20 AI requests fail in production, with systems continuing to run and returning outputs that appear correct. That last point matters: these aren't visible failures. They're silent ones.
The Real Problem:
Data Built for Humans, Not AI
Traditional data infrastructure was designed with a specific consumer in mind: a human analyst, or a deterministic reporting pipeline. Clean, structured, correctly-typed data fed into a dashboard or a SQL query. The bar for "good enough" was: can a person or a pre-written query extract the right number?
AI demands something fundamentally different.
When a language model or a statistical AI system interacts with your data, it doesn't run pre-written queries. It reasons. It draws inferences. It synthesises across sources. It interprets ambiguous fields and fills gaps with probabilistic logic. The quality bar for that kind of reasoning is categorically different from the bar for producing a monthly report.
The traditional data quality framework — often called the medallion architecture, with its bronze, silver, and gold tiers — was built for batch pipelines and human analysts. A perfectly clean "gold" table can still be completely useless for AI, because it lacks the semantic context the model needs to reason from it reliably.
What AI actually requires is:
Semantic coherence — the model needs to understand what a field means in business context, not just its data type
Inferential density — enough signal in the data for reliable reasoning, not just enough data for a correct aggregation
Contextual consistency — the same concept meaning the same thing across different source systems and schemas
Temporal reliability — data fresh enough for the inference being made, which is often a different standard than the reporting cycle
Volume awareness — sparse but well-understood data behaves very differently to dense but semantically ambiguous data
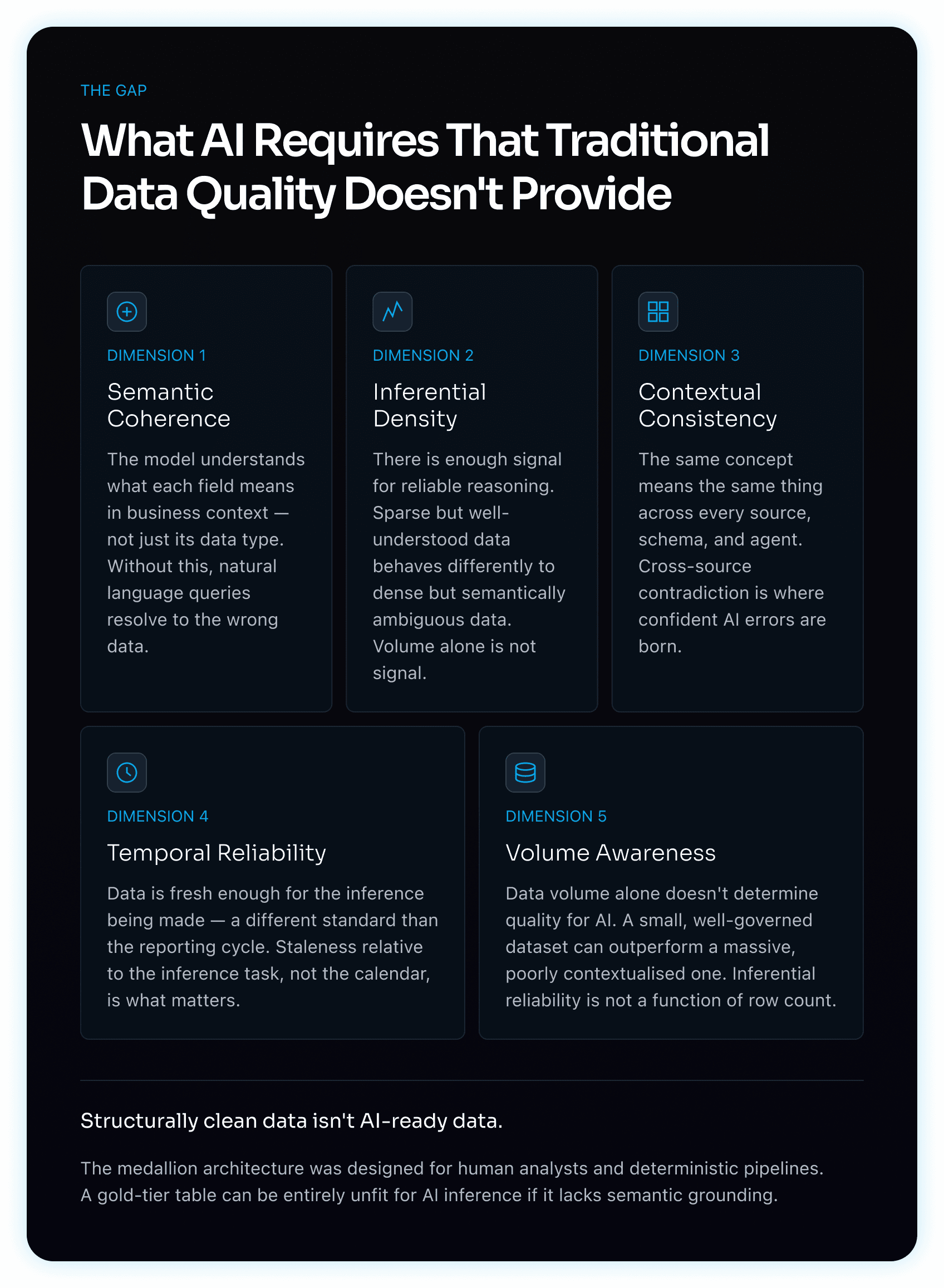
Visual 1 — AI Readiness Dimensions
A diagram presenting the five dimensions that distinguish AI-ready data from traditionally clean data: Semantic Coherence, Inferential Density, Contextual Consistency, Temporal Reliability, and Volume Awareness. Each dimension identifies a quality requirement that deterministic data pipelines do not address but AI systems depend on for reliable inference.
This is not a small upgrade to existing data pipelines. It is a different quality framework entirely.
The Natural Language Problem
One of the most underappreciated dimensions of this gap is natural language. When users ask AI systems questions in plain English, they're expecting the system to translate intent into accurate retrieval and reasoning. But that translation depends entirely on whether the underlying data has been made legible to a language model.
Field names like cust_flag_2, schema columns inherited from a migration in 2014, or metrics that mean different things in different regional business units — these are invisible obstacles that break natural language interfaces completely. The model doesn't know what it doesn't know. It will confidently answer the question using whatever it can find, regardless of whether that data is the right data.
The result is what we call confident errors at scale — AI outputs that are wrong, but don't look wrong, because the system has no mechanism to flag its own uncertainty about the data underneath it.
The Expectation Gap
There's a compounding factor that makes the natural language problem harder to diagnose: users arrive with expectations shaped by consumer LLMs.
ChatGPT, Claude, and Gemini answer natural language questions fluently because they've been trained on vast public corpora — billions of documents, articles, codebases, and web pages. When a user asks a general question, the model draws on an enormous, well-structured knowledge base that has been refined through extensive training and fine-tuning. The experience is fast, coherent, and confident.
Enterprise users bring that same expectation to their internal data. They expect to ask "what was our fulfilment rate in Q3 across the northern region?" and get an immediate, accurate answer. The experience of using a public LLM has established a baseline — natural language in, reliable answer out — and there is no reason from the user's perspective why their own company's data should behave differently.
But it does. Enterprise data wasn't part of any LLM's training. The model has no pre-existing understanding of what your schema means, what your business logic is, or how your metrics are defined. Every natural language query over internal data has to be grounded at runtime — resolved against a governed context layer that translates user intent into accurate retrieval. Without that layer, the model doesn't fail visibly. It guesses. It draws on the closest thing it knows, which may be a structural pattern from its training rather than the specific business definition your query requires. The output looks right. It often isn't.
This is why natural language interfaces over enterprise data are not a model problem. They are a data readiness problem. The model is doing exactly what it was designed to do. The missing piece is the governed, semantically coherent data foundation that makes the model's reasoning trustworthy over your specific data estate.
The Performance Problem
There's a second dimension that gets even less attention: latency.
Traditional analytics accepts waiting. A complex data warehouse query might take minutes. A scheduled report might run overnight. Human analysts have learned to build their workflows around these constraints.
AI-native workflows don't work that way. When a user asks a natural language question and expects an answer in seconds, a 90-second query response time is a broken experience. When an AI agent is orchestrating across multiple data sources to produce a synthesised output, each layer of latency compounds. The user experience degrades, trust erodes, and the workflow quietly reverts to the manual process the AI was supposed to replace.
Organisations that have built their AI analytics on top of under-optimised data infrastructure discover this the hard way. The model is fast. The data layer is not. And the user doesn't care which part is slow.
How LLMs Solve This Problem — And Why Enterprises Can't Do the Same
Understanding why enterprise data fails AI systems requires understanding how large language models handle ambiguity at scale — and why that mechanism does not transfer to the enterprise context.
LLMs develop semantic understanding through exposure to enormous volumes of diverse text. When a model encounters an ambiguous term, an inconsistently used concept, or a field with no explicit definition, it resolves that ambiguity statistically — drawing on billions of co-occurrences across its training corpus to infer meaning from context. The model has seen the word "churn" used in telecommunications contexts thousands of times. It has encountered "margin" in financial contexts across millions of documents. It has processed enough variation to build robust, generalised representations of these concepts that hold up across different phrasings and contexts.
This is not understanding, in a human sense. It is pattern resolution at scale. And it works precisely because the scale is massive — the sheer volume of training data means that even rare or ambiguous constructs appear often enough for the model to form a reliable statistical representation of them.
Enterprise data does not have this property. An Enterprise organisation's internal data estate might comprise tens of millions of records across dozens of systems. That is not small in operational terms, but it is orders of magnitude below the threshold at which statistical pattern resolution becomes reliable. More critically, enterprise data is not diverse — it is highly domain-specific, reflecting the idiosyncratic terminology, business logic, and schema decisions of a single organisation. A field named adj_rev_exc_ret means something precise to the finance team that built it. There is no training corpus large enough, and no general-purpose model powerful enough, to infer that meaning reliably from structure alone.
The implications are significant. An LLM deployed over enterprise data without explicit semantic grounding will behave as if it understands the data — producing fluent, confident outputs — while actually resolving ambiguity through general statistical inference rather than domain-specific knowledge. The outputs will be coherent. They will frequently be wrong in ways that are difficult to detect without deep familiarity with the underlying data.
The resolution is not to train a larger model. It is to make the semantic context explicit. Where LLMs compensate for ambiguity through scale, enterprise AI systems must compensate through precision — governed metadata, curated business definitions, lineage-aware context layers, and domain-specific grounding that encodes what the data actually means rather than leaving the model to infer it. The goal is to reduce the inferential burden on the model by doing the semantic work in the data layer, before the model ever sees the data.
This reframes the data readiness problem architecturally. It is not about cleaning data to a higher standard. It is about building a semantic layer that gives AI systems the contextual grounding that LLMs derive from scale — through deliberate engineering rather than statistical approximation.
The Domain-Specific Model Fallacy
A common response to general-purpose model failures is to reach for a domain-specific one. If a general LLM can't handle insurance data reliably, the reasoning goes, then a model fine-tuned on insurance corpora should close the gap. It doesn't — and understanding why is important.
A domain-specific model knows the industry's language. It understands what "loss ratio," "ceded premium," or "incurred but not reported" mean in general insurance terms. It has been trained on enough sector-specific text to produce outputs that sound precisely right to a domain expert. That capability is real and not without value.
What it cannot know is what those terms mean in a specific organisation's data estate. It doesn't know that a particular insurer's adj_loss_ratio field excludes catastrophe events after a methodology change in 2019. It doesn't know that two source systems use "written premium" and "gross written premium" interchangeably despite them representing different figures. It doesn't know that the reinsurance team redefined "exposure" three years ago and the legacy definition still persists in several historical tables.
Domain knowledge and organisational data context are entirely different things. Fine-tuning on industry corpora improves the model's priors for general concepts — it does nothing to resolve the idiosyncratic schema decisions, historical anomalies, and cross-system inconsistencies that are unique to that organisation. Those cannot be trained away. They can only be addressed in the data layer itself.
The failure mode is also harder to catch. A domain-specific model produces outputs using correct terminology, in the correct professional register, structured in ways that look entirely credible to a subject matter expert. The error — silently resolving an ambiguous field against the wrong definition — is invisible in the output. It only surfaces when someone with deep knowledge of the underlying data happens to question a specific number. At scale, most won't.
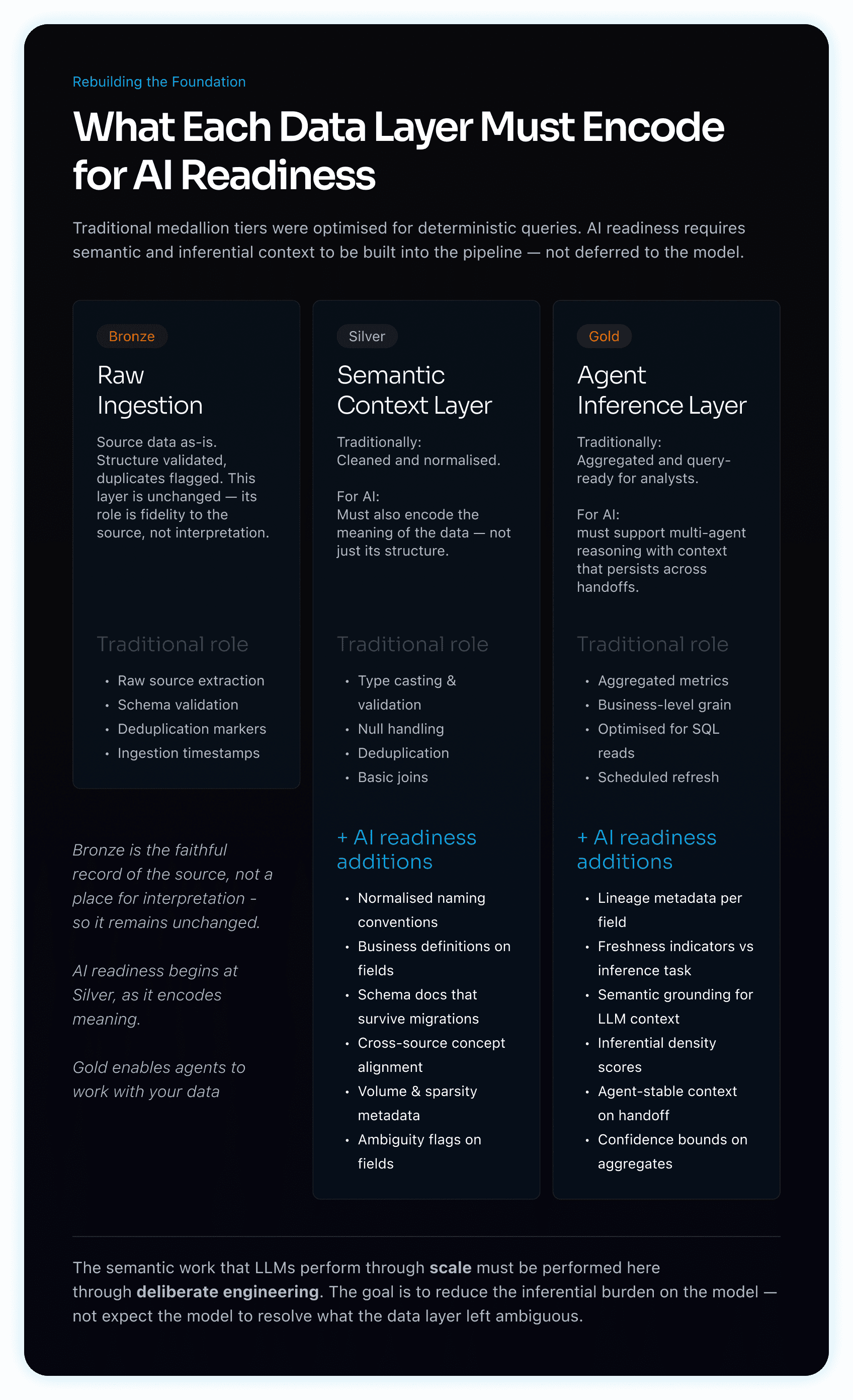
Visual 2 - Data Layers
A three-column diagram showing how the Bronze, Silver, and Gold data tiers must evolve to support AI readiness, contrasting each layer's traditional role with the additional requirements AI systems introduce. Silver must encode semantic context — naming conventions, field definitions, cross-source alignment — while Gold must support agent inference through lineage metadata, freshness indicators, and context that persists across model handoffs.
The phrase "AI-ready data" is widely used and rarely defined with precision.
AI readiness is not a checklist or a migration project with a completion date. It is a quality standard — one that has to be built into the data infrastructure itself, and maintained continuously as data volumes, schemas, and business definitions evolve.
Operationally, it means data has sufficient semantic context for a model to reason from it correctly — not merely sufficient structure for a human analyst to read it. It means pipelines are optimised for the latency requirements of interactive AI experiences, not batch reporting cycles. It means there is a governed layer between raw data and AI systems capable of detecting, flagging, and recovering from quality failures before those failures propagate into model outputs.
The distinction that matters most is between data built for deterministic retrieval and data built for probabilistic inference. These are not the same standard. A dataset that satisfies every criterion of a traditional gold-tier data model can be entirely unfit for AI reasoning if it lacks semantic coherence, inferential density, or contextual consistency across source systems.
Organisations that have closed this gap — and the research consistently shows they are a small minority — share a common characteristic: they addressed the data foundation before the AI deployment conversation began, not after it stalled.
Conclusion
The dominant failure mode in enterprise AI is not model quality, compute availability, or organisational change management. It is a structural mismatch between the quality requirements of AI systems and the data infrastructure most enterprises have inherited.
The natural response — deploy a more capable model and let it handle the ambiguity — is not a viable solution at enterprise scale. LLMs resolve ambiguity through statistical inference across billions of training examples. Enterprise data estates do not provide the volume or diversity required for that mechanism to work reliably over domain-specific schemas and business logic.
The correct response is architectural. The semantic work that LLMs perform implicitly through scale needs to be performed explicitly through governed data engineering — built into the data layers themselves rather than deferred to the model at inference time.
This requires a meaningful expansion of what silver and gold data tiers are expected to deliver. Traditionally, silver has meant structurally clean and deduplicated data. For AI readiness, silver must also encode semantic context: normalised naming conventions, business definitions attached to fields, schema documentation that survives system migrations, and cross-source consistency that allows the same concept to be resolved identically regardless of origin. The goal at this layer is to reduce the inferential burden on any downstream model to near zero for structural and definitional questions.
Gold has traditionally meant aggregated, query-ready data optimised for human analysts and deterministic pipelines. For AI readiness, gold must go further — encoding the inferential context that agents require: temporal reliability indicators, lineage metadata that allows a model to assess data freshness relative to the inference being made, and semantic grounding sufficient for multi-agent orchestration where context must remain consistent across handoffs.
The distinction that matters is between cleaning data and contextualising it. A structurally clean dataset with no semantic layer is not AI-ready. A semantically rich dataset — even one with gaps — can support reliable AI inference if those gaps are explicitly represented rather than left for the model to resolve through guesswork.
Organisations that treat data readiness as a foundational engineering discipline — building semantic inference into the pipeline rather than expecting the model to supply it — are the ones for whom AI deployment becomes a compounding advantage rather than a recurring pilot.
Get a clearer view of your performance with real-time data, powerful visualizations, and effortless collaboration.
Get Started